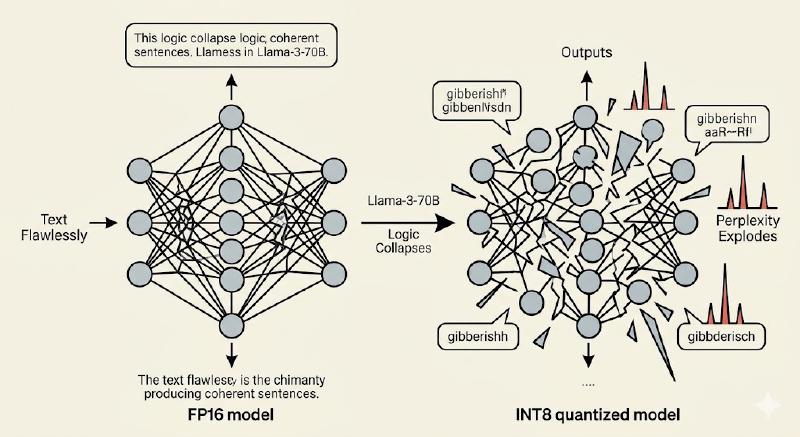
You just quantized a new Llama-3-70b from FP16 to INT8. Memory usage is slashed to half and the speed of off the track (compared to the FP16). You gave the exact same test prompt the FP16 that handled flawlessy… and the model spits out pure gibberish text.
Sentences collapse. Logic evaporates just like that. It confuses with basic facts it once knew cold. Perplexity doesn’t rise a little, but it explodes.
The model doesn’t just lose a few decimals. It lost its mind.
This is not a rare bug or any bad luck. It is what happens when you apply the simple math of quantization naively to a real LLM. The delicate change of weights and activations that made the model smart gets shattered by rounding and clipping.
So the big question is:
How do we quantize without destroying the model’s logic?
Two rival philosophies that solve this exact problem: Post-Training Quantization (PTQ), the “fix it later” school, and Quantization-Aware Training (QAT), the “train it right” school.
By the end of this post you’ll know exactly when to reach for each technique and why one can turn a genius into an idiot while the other keeps the brilliance intact.
The Core Enemy: Clipping and Outliers#
Before we get into the two clamps, we need to understand clipping, the villain of the story.
Every quantized tensor lives inside a finite range \([r_{min}, r_{max}]\). Anything outside is clamped:
where \(s = \dfrac{r_{max} - r_{min}}{q_{max} - q_{min}}\) is the scale and \(z\) is the zero point.
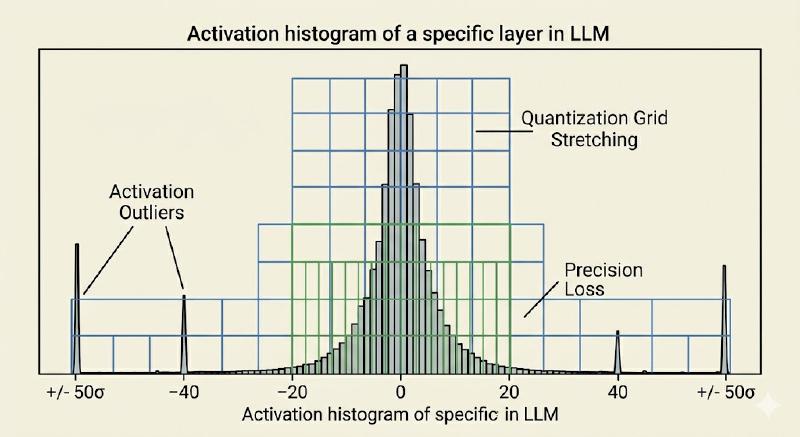
In LLMs, the real killer is activaion outliers. While 99% of the values in a transformer sit comfortably inside \(\pm 3\sigma\), a tiny fraction can spike to \(\pm 50\sigma\) or more, especially in attention and feed forward layers of bigger models. These spikes force the entire scale factor to stretch, crushing the common values into just a handful of coarse bins. The result, massive quantization noise exactly where the model is trying to do its most delicate work.
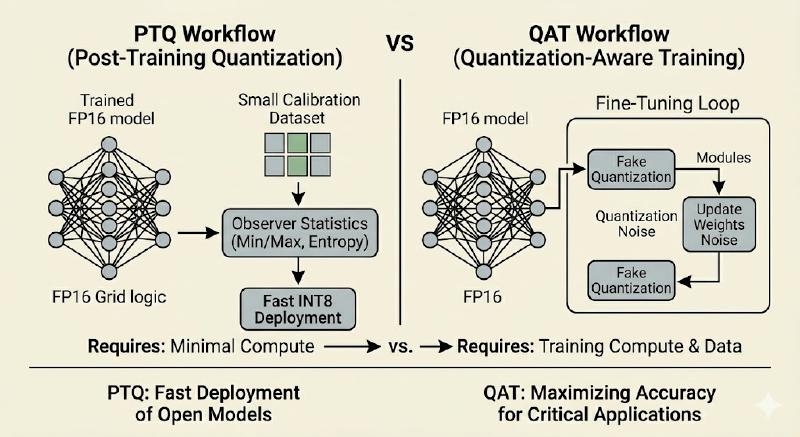
Post-Training Quantization (PTQ): The “Fix It Later” Way#
PTQ is one of the most important technique in modern LLM Quantization world. You take a fully trained FP16 or FP32 model, run it once on a small calibration dataset (usually 128-512 representative sequences from C4, WikiText, or your own data), and let the framework adjust its scales.
How it works in practice#
- Observer nodes are inserted after every weight and activation tensor (PyTorch calls them
MinMaxObserver,HistogramObserver,PerChannelMinMaxObserver, etc.) - During a single forward pass on calibration data, observers record statistics: min/max, 99.9th percentile (to ignore extreme outliers), or entropy (KL-divergence minimisation).
- Scales and zero-points are computed once and frozen.
- The model is converted to real
INT8orINT4tensors (or fake-quantized for testing).
Hardware reality
PTQ is inference only. No gradients, no optimizer states, no extra VRAM. On an RTX 4090 you can quantize a 70B model to 4-bit in under 10 minutes and get 2–3× higher tokens/second immediately. That is why GPTQ, AWQ, and GGUF (K-Quants) are all PTQ descendants.
The Catch Because the model never saw quantization noise during training, it has zero robustness. A single bad calibration run or a domain shift (chat vs. code) can destroy performance. Naive PTQ on Llama-3-70B can easily add +0.5–1.5 perplexity points at 4-bit.
Quantization-Aware Training (QAT): The “Train It Right” Way#
As the name says, QAT is whole different approach compared to PTQ. Instead of surprising the model with quantization at inference time, we simulate the exact quantization noise during training or fine-tuning.
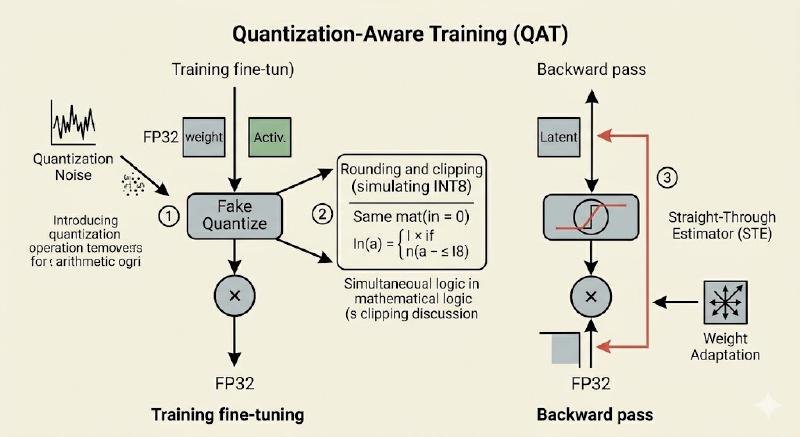
The two magic components#
1. Fake Quantization#
In the forward pass we actually perform the full quantize and then dequantize round-trip:
The output
\(\hat{r}\) is still in FP32 or FP16 for the next layer, but it carries the exact rounding and clipping error the real integer hardware will see.
2. Straight-Through Estimator(STE)#
The rounding function has derivative zero almost everywhere, where gradients would die. STE is the elegant hack:
In code it is literally “identity in the backward pass.” PyTorch implements this with FakeQuantize modules.
Because the model now sees the quantization error every step, the optimizer gently nudges weights and activations into ranges that are quantization-friendly. Outliers are suppressed naturally. Model learns to live with the noise. This results, QAT almost always recovers within 0.1–0.3 perplexity of the FP16 baseline even at INT8, and modern variants can push 4-bit performance extremely close to full precision.
Unlike PTQ, where a decent RTX 4090 can do the quantization, you need real training compute and a few epochs of fine-tuning.
Comparison#
| Aspect | PTQ | QAT |
|---|---|---|
| Training required | None | Yes (fine-tuning or from-scratch) |
| Calibration Data | 128-512 samples | Full training/fine-tuning dataset |
| Time to quantize | 5–30 minutes | 10–100+ hours |
| Accuracy (4-bit) | Good with smart calibration | Excellent. Learns to suppress outliers |
| Hardware friendliness | Perfect for inference servers | Requires full training stack |
| Typical use case | Deploying existing open models | New model development or domain adaptation |
Short Code Demos (PyTorch)#
PTQ with observer nodes (static quantization)
import torch
from torch.ao.quantization import prepare, convert, get_default_qconfig
model = MyTransformer() # your FP32 model
model.qconfig = get_default_qconfig('fbgemm')
prepared_model = prepare(model, inplace=False) # inserts observers
# Run calibration
with torch.no_grad():
for batch in calib_loader: # 128–512 samples
prepared_model(batch)
quantized_model = convert(prepared_model) # real INT8
QAT with fake quantization
from torch.ao.quantization import QConfig, FakeQuantize
from torch.ao.quantization.observer import MinMaxObserver
qconfig = QConfig(
activation=FakeQuantize.with_args(observer=MinMaxObserver, quant_min=-128, quant_max=127),
weight=FakeQuantize.with_args(observer=MinMaxObserver, quant_min=-127, quant_max=127)
)
model.qconfig = qconfig
qat_model = prepare(model, inplace=False) # fake quant nodes
# Normal training loop — model now sees quantization noise
for epoch in range(num_epochs):
for batch in train_loader:
loss = qat_model(batch)
loss.backward()
optimizer.step()
quantized_model = convert(qat_model)
Takeaway#
PTQ is often considered as pragmatic choice for 99% of today’s open source LLM deployments. It is fast, cheap, and importantly good enough with smart calibration
QAT is the gold-standard way when you control the training process. It turns quantization from disadvantage to advantage by learned features.
Understanding this split is the key that unlocks everything else in this quantization world. In next blog, we leave the theory behind and dive into group-wise quantization, K-Quants, and why a 70B model can finally process easily on your average laptop.
*Visuals generated through Google Gemini
