Imagine trying to run Meta’s Llama 3 70B locally. In its native FP16 (half-precision floating-point) format, the weights alone consume:
That’s not a typo.
Even the best consumer GPU today (an RTX 4090) tops out at 24 GB. Two enterprise A100-80GB cards still fall short. And that’s before you add KV cache, optimizer states, or activations. The model simply won’t fit, let alone run at usable speed.
This is the memory-bandwidth bottleneck in a nutshell. Modern LLM inference is rarely compute-bound; it is memory-bound. Loading and moving 140 GB of weights between GPU HBM and Tensor Cores dominates latency. Every extra byte you load costs real time and real money.
Quantization is the bridge: we deliberately reduce the numerical precision of the model’s weights (and sometimes activations) from 16-bit floats down to 8-bit, 4-bit, or even lower integers. The result? Dramatic memory savings and much higher throughput, usually with only a tiny, recoverable drop in quality.
Precision: From FP32 to INT8#
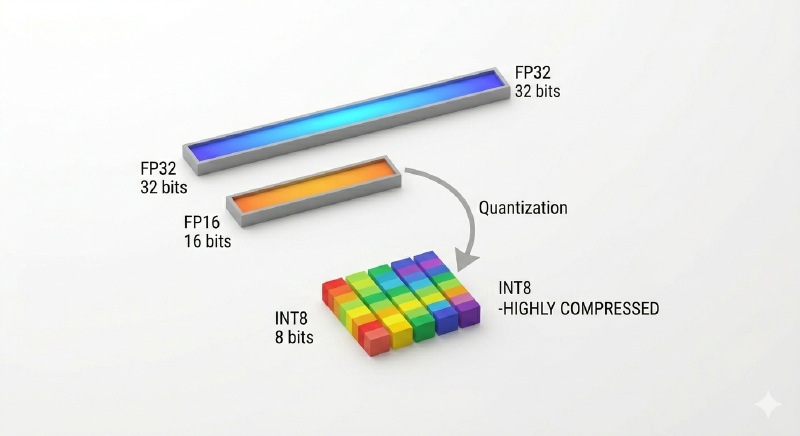
Let’s talk about bits
- FP32(full precision): 32 bits per value (1 sign + 8 exponent + 23 mantissa). Dynamic range ≈ \(\pm 3.4 * 10^{38} \), precision down to ~7 decimal digits.
- FP16(half precision): 16 bits (1 sign + 5 exponenet + 10 mantissa). Still huge dynamic range, but only ~3–4 decimal digits of precision.
- INT8(signed 8-bit integer): just 8 bits total. Representable values:
–128to+127.
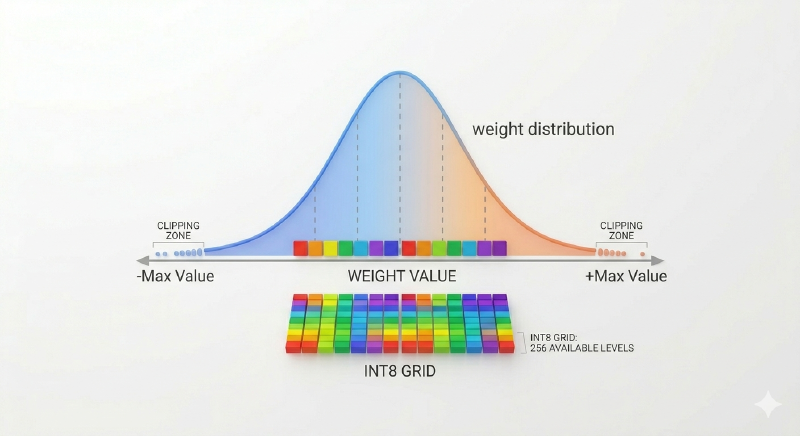
Why does this work? Because the weight distributions in trained LLMs are highly peaked around zero (roughly normal or Laplace) with small variance. The overwhelming majority of values sit comfortably within a narrow band. We don’t need 65,536 possible exponent combinations when 256 evenly spaced levels capture 99 % of the signal.
Hardware reality sidebar
Tensor Cores on NVIDIA Ampere and later GPUs are optimized for INT8 and INT4 matrix multiplies. An INT8 GEMM can be 2–4× faster and 2× more energy-efficient than the equivalent FP16 operation because:
- Integer arithmetic is simpler (no exponent handling).
- The hardware can pack two
INT8values into the same 16-bit lane. - Memory traffic is halved.
In short: the GPU is literally built to love low-precision math.
The Rounding Analogy — and Why It’s Not Just Rounding#
Think of quantization like rounding your bank balance to the nearest dollar instead of keeping cents. You lose a little fidelity, but the “big picture” (how much money you actually have) stays intact.
In neural networks the same principle applies, except we are rounding millions of tiny numbers that interact through matrix multiplies. The trick is to make the rounding as “smart” as possible so the downstream computations barely notice.
The Math: Scale S and Zero-Point Z#
The core operation is affine (asymmetric) quantization:
where:
r= real-valued weight or activation (FP16/FP32),q= quantized integer (e.g.,INT8),s= scale factor (a singleFP32number per tensor or per group),z= zero-point (an integer offset, usually chosen so that 0 in real space maps close to the middle of the integer range),- \( round( \cdot ) \) = nearest-integer rounding,
- \( clamp ( \cdot ) \) keeps
qinside the representable range ([–128,127]forINT8).
To get the original value back (dequantization):
$$\hat{r} \approx s \cdot (q - z)$$Most production pipelines use symmetric quantization \((z = 0) \) for simplicity and speed:
The entire process is deterministic and differentiable (with the Straight-Through Estimator trick, that’s a discission for another blog). So we can quantize a model once and run it forever.
Perplexity: The Score That Matters#
We quantify “how much smarter the model feels” with perplexity on a held-out validation set. A well-quantized 4-bit Llama-3-70B might increase perplexity by < 0.1 points compared with FP16 - imperceptible to humans. That’s the magic: we trade a microscopic amount of numerical fidelity for gigabytes of memory and tokens-per-second.
Tiny Code Demo (PyTorch)#
Here’s the essence in five lines — the same math that powers bitsandbytes, torch.quantization, and GGUF:
import torch
def quantize_per_tensor(x: torch.Tensor, bits: int = 8):
q_min, q_max = - (2**(bits-1)), (2**(bits-1)) - 1
scale = (x.abs().max() / q_max).clamp(min=1e-8) # S
zero_point = 0 # symmetric
q = torch.round(x / scale).clamp(q_min, q_max).to(torch.int8)
return q, scale, zero_point
def dequantize(q: torch.Tensor, scale: torch.Tensor, zero_point: int = 0):
return scale * (q - zero_point) # back to FP32/FP16
That’s it. Load the model, call quantize_per_tensor on every weight tensor, store the tiny scale factors (they add almost zero overhead), and you just cut memory in half.
Where We’re Going Next#
This was the why and the how at the conceptual level. In next we’ll meet the two big families Post-Training Quantization (PTQ) vs Quantization-Aware Training (QAT), and see why naive rounding sometimes destroys a model’s reasoning while a smarter calibration dataset saves it. Then we’ll dive into the 4-bit revolution that finally put 70B models on laptops.
Quantization isn’t magic. It’s just an extremely well-engineered numerical hack that respects both the statistics of neural weights and the realities of silicon. Once you see the math, you’ll never look at a 140 GB model the same way again.
Credits:
*Visuals generated through Google Gemini
